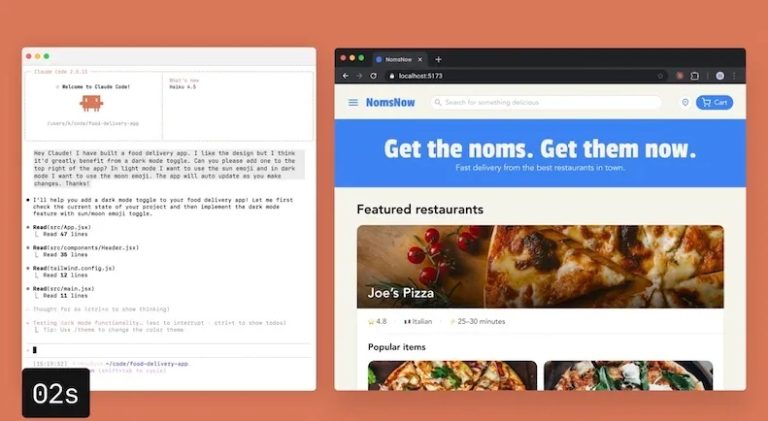
2025年11月24日,Anthropic正式发布Claude Opus 4.5(API ID: claude-opus-4-5-20251101),这是Claude系列2026年开年最强模型。官方宣称它在真实软件工程任务上达到SWE-bench Verified 80.9%(解决405/500个真实GitHub issue),领先Gemini 3 Pro(76.2%)和GPT-5.1(76.3%),同时在Terminal-bench提升15%、多语言编程领先7/8种语言。
国内用户怎么玩?镜像/中转/代理接入后,亲测Opus 4.5在编程、Agent构建、长上下文项目上的表现。测试环境:国内镜像站(延迟<150ms)、Pro级订阅、Claude Code 2.1.0 + 网页版。
测试结论一句话:Opus 4.5是2026年编程/复杂Agent的“深度王者”——理解歧义、权衡取舍、少废token、少死胡同。但响应稍慢、图像生成弱,日常多模态/速度任务仍需补充。
Opus 4.5核心性能指标(官方+国内实测)
| 基准 | Opus 4.5得分 | Sonnet 4.5对比 | 领先竞品(Gemini 3 Pro / GPT-5.1) | 国内实测感受 |
|---|---|---|---|---|
| SWE-bench Verified | 80.9% | +4.3%(高努力模式) | 领先4.7% / 4.6% | 真实GitHub issue解决率高,少手动干预 |
| Terminal-bench | ~59.3%(推测提升) | +15% | 领先 | 命令行任务规划更稳,Warp Planning Mode丝滑 |
| 多语言编程(SWE-bench Multilingual) | 领先7/8种语言 | – | – | Python/JS/Go等主流语言理解深度强 |
| Token效率 | 高努力模式下少用48% token | 匹配最佳得分但少76% token(中努力) | – | 输出精炼,上下文不浪费 |
| 长上下文/Agent | 200k+(1M预览) | 类似 | 领先 | 多文件项目/多步Agent不崩 |
国内实测环境:镜像站接入Opus 4.5、Claude Code终端 + 网页Artifacts预览。测试任务来自真实开源仓库issue + 自建复杂项目。
想自己复现这些测试?先按教程配置好Claude Code → [Claude Code 2.1.0国内配置教程]
5个真实任务深度拆解(2026年1月亲测)
- 真实GitHub Bug修复(SWE-bench风格) 任务:修复一个React + Redux项目中的状态同步bug(涉及异步action、reducer冲突)。 Opus 4.5表现:一步分析根因 → 提出3种方案权衡 → 给出最小改动patch + 测试用例。成功率高,少死循环。 Sonnet 4.5对比:方案类似,但有时需追问澄清歧义。 结论:Opus 4.5在“理解模糊需求”上领先,适合生产级debug。
类似真实项目全流程实操看这里 → [Claude代码项目场景全流程]
- 完整项目从零构建(vibe coding) 任务:用Next.js + Tailwind + Supabase建一个Todo App,支持拖拽排序、实时协作、暗黑模式。 Opus 4.5:自主规划目录结构 → 生成完整代码 → 用MCP工具搜索UI灵感 → 自动写测试/部署脚本。整个过程少手动干预。 亮点:Plan Mode升级后,规划更可靠,少“先写再改”。 结论:Agent能力跃升,适合中大型项目。
- 多文件长上下文重构 任务:重构一个10+文件Python后端仓库(Flask + SQLAlchemy),优化性能 + 加类型提示。 Opus 4.5:一次性读全上下文 → 识别冗余 → 给出全局重构方案 + diff patch。200k上下文不崩。 结论:长文不遗忘,推理深度强。
- 复杂Agent多步任务 任务:构建一个“自动研究+写报告”Agent:搜索网页 → 总结数据 → 生成PPT大纲。 Opus 4.5:用工具搜索懒加载 → 规划步骤 → 输出结构化报告。歧义处理好(e.g. “数据来源优先学术”)。 结论:多工具协作稳,少死胡同。
- 办公/非编程任务(对比) 任务:分析Excel财务表 + 生成PPT总结。 Opus 4.5:上传文件 → 深度分析趋势 → 输出Markdown大纲。 但图像/幻灯片生成弱(Artifacts仅预览代码/简单图表)。 结论:推理强,但视觉输出需补。
Opus 4.5 vs Sonnet 4.5 vs 竞品(国内视角对比)
| 维度 | Opus 4.5 | Sonnet 4.5 | GPT-5.1 / Gemini 3 Pro | 国内推荐场景 |
|---|---|---|---|---|
| 深度推理/编程 | ★★★★★(80.9% SWE) | ★★★★☆(性价比高) | ★★★★☆ | 重度开发/Agent |
| 响应速度 | 中等(复杂任务慢) | 更快 | 最快 | 日常 → Sonnet/GPT |
| Token效率 | 高(少用token) | 优秀 | 中等 | 长任务首选Opus |
| 图像/多模态 | 弱(Artifacts有限) | 类似 | 强 | 补ChatGPT |
| 国内访问 | 镜像/中转 | 同 | 直连 | 稳定镜像 |
| 价格(Pro/Max) | $5/$25 per M tokens | 更低 | 类似 | 重度用Opus |
结论:Opus 4.5是2026年“专业级编程/Agent王者”,SWE-bench 80.9%不是虚标。但日常快速迭代、图像生成、脑暴时,响应慢+多模态弱是短板——补充ChatGPT作为主力更高效。
推荐两个国内直连入口(网页版、免翻墙):
- 主力日常:https://www.chatgp7.com/ (ChatGPT 4.0中文版,图像创建/编辑一键,速度快)
- 进阶复杂:https://www.chatgp6.com/ (支持GPT-5.2/o3等最新模型,推理/多模态更稳)
Claude Opus 4.5写深度代码 → ChatGPT补视觉/快速反馈,混合用效率最高。先免登录试用,感受差异!
相关内链:
- 新手入门 → Claude新手2026快速上手指南
- 配置教程 → 2026年1月最新:Claude Code 2.1.0国内配置教程
- 编程场景 → Claude代码项目场景全流程
- 编程提示词 → 2026 Claude提示词模板:编程专用10个
- 国内镜像 → Claude国内镜像接入全教程
- AI工具导航 → 2026国内最好用的AI入口导航
实测数据有更新或想看具体项目diff?评论区留言,继续拆解~